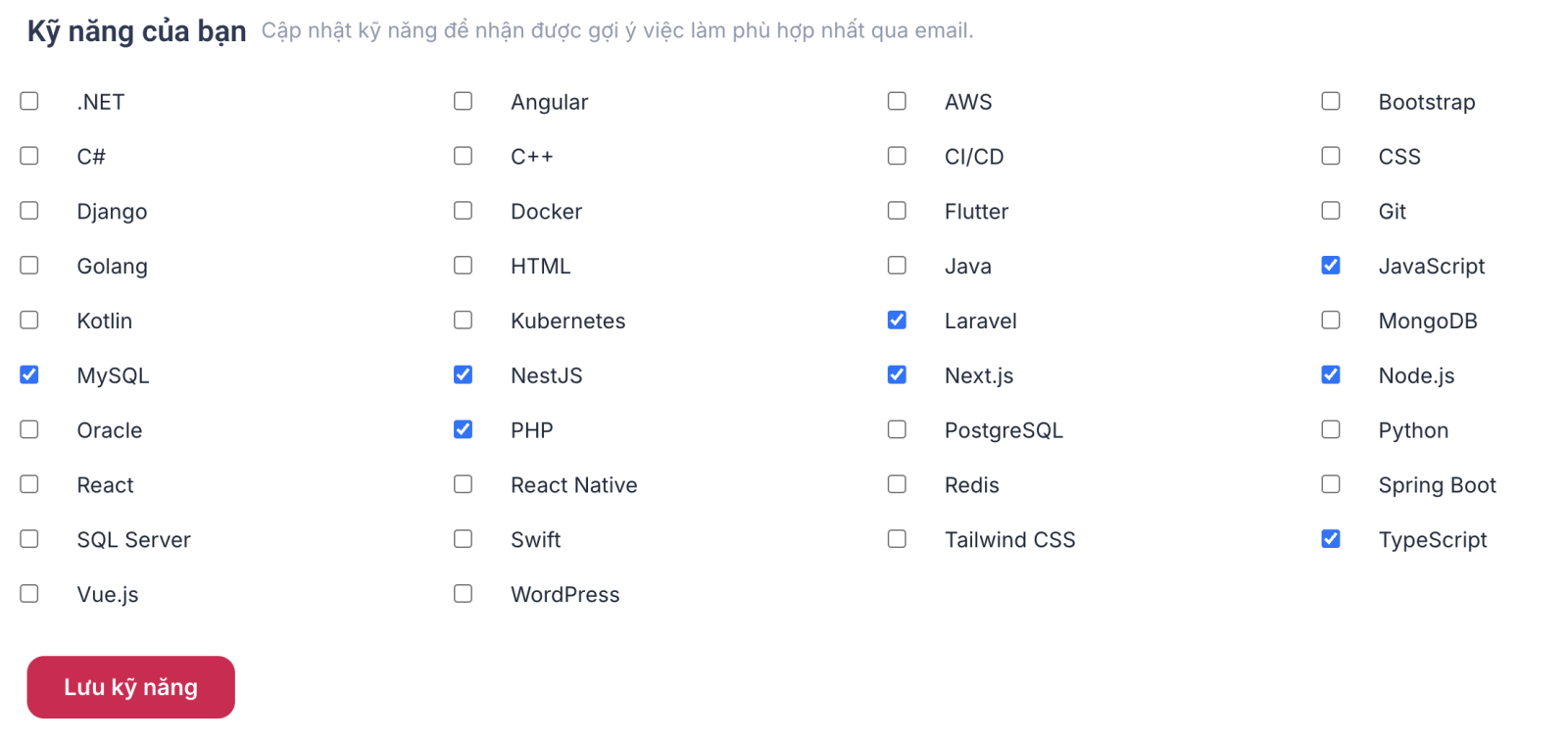
Thư Viện Câu Hỏi Phỏng Vấn
Tổng hợp các câu hỏi tuyển dụng thực tế theo nhiều cấp độ từ Entry đến Expert để bạn tự tin chinh phục nhà tuyển dụng.
Cấu trúc dữ liệu Heap (Min-Heap / Max-Heap) là gì? Thao tác thêm phần tử (Heapify-up) và xóa phần tử gốc (Heapify-down) có độ phức tạp là bao nhiêu?
Heap là một cây nhị phân gần như hoàn chỉnh (thường được biểu diễn dưới dạng mảng để tiết kiệm bộ nhớ) thỏa mãn tính chất:
- Max-Heap: Giá trị của node cha luôn lớn hơn hoặc bằng giá trị các con của nó (Gốc là giá trị lớn nhất).
- Min-Heap: Giá trị của node cha luôn nhỏ hơn hoặc bằng giá trị các con của nó (Gốc là giá trị nhỏ nhất).
- Thao tác Thêm (Heapify-up): Phần tử mới được chèn vào cuối cây (cuối mảng). Sau đó, nó được so sánh với cha và hoán vị đi lên nếu vi phạm thuộc tính Heap. Chiều cao tối đa của cây là log n, nên độ phức tạp là O(log n).
- Thao tác Xóa gốc (Heapify-down): Thay thế phần tử gốc bằng phần tử cuối cùng của mảng, sau đó xóa phần tử cuối cùng này. Tiếp theo, so sánh gốc mới với các con và hoán vị đi xuống với con lớn hơn (hoặc nhỏ hơn đối với Min-Heap) để tái lập cấu trúc Heap. Độ phức tạp là O(log n).
Làm thế nào để kiểm tra một số nguyên dương N có phải là lũy thừa của 2 (Power of Two) chỉ bằng các phép toán Bitwise trong O(1)?
Một số nguyên dương N là lũy thừa của 2 nếu và chỉ nếu biểu diễn nhị phân của nó chỉ chứa duy nhất một bit 1 (ví dụ: 4 = 100_2, 8 = 1000_2, 16 = 10000_2).
- Giải pháp Bitwise: Sử dụng biểu thức
(N & (N - 1)) == 0. - Giải thích cơ chế:
- Số N (lũy thừa của 2) có dạng:
100...0. - Số N - 1 sẽ có dạng:
011...1(tất cả các bit sau bit 1 của N đều bị đảo ngược). - Khi thực hiện phép toán AND bitwise (
&):(100...0) & (011...1) = 000...0. - Đối với bất kỳ số nào không phải là lũy thừa của 2, biểu diễn nhị phân của nó sẽ có nhiều hơn một bit 1. Do đó, phép toán
N & (N - 1)sẽ giữ lại các bit 1 phía trước và không thể cho kết quả bằng 0.
- Số N (lũy thừa của 2) có dạng:
- Lưu ý: Cần kiểm tra thêm điều kiện N phải lớn hơn 0. Hàm hoàn chỉnh:
return (N > 0) && ((N & (N - 1)) == 0). Độ phức tạp thời gian và không gian đều là O(1).
Cấu trúc dữ liệu Trie (Prefix Tree) hoạt động như thế nào? Tại sao nó cực kỳ hiệu quả cho tính năng Autocomplete và Search Suggestions?
Trie (Cây tiền tố) là một cây có cấu trúc phân nhánh đặc biệt dùng để lưu trữ một tập hợp các chuỗi ký tự, trong đó các node chia sẻ chung tiền tố (prefix) với nhau.
- Cơ chế hoạt động: Mỗi node của Trie đại diện cho một ký tự. Node gốc không chứa ký tự nào. Đường đi từ gốc đến một node cụ thể biểu diễn tiền tố hoặc từ hoàn chỉnh được lưu trữ. Mỗi node sẽ chứa một mảng liên kết các con trỏ tới các ký tự tiếp theo và một biến boolean đánh dấu kết thúc từ (isEndOfWord).
- Tại sao hiệu quả cho Autocomplete:
- Tốc độ tìm kiếm từ có độ dài L chỉ là O(L), hoàn toàn độc lập với số lượng từ N được lưu trong Trie (ví dụ: tìm từ trong 1 triệu từ vẫn chỉ tốn số bước bằng số ký tự của từ đó).
- Dễ dàng tìm kiếm tất cả các từ bắt đầu bằng một tiền tố cho trước bằng cách đi đến node đại diện cho tiền tố đó, sau đó duyệt DFS/BFS để thu thập tất cả các từ con bên dưới. Điều này giúp tối ưu hóa tối đa thời gian phản hồi cho các hệ thống gợi ý từ khóa thời gian thực.
Giải thuật Quay lui (Backtracking) khác gì so với duyệt vét cạn (Brute Force)? Giải thích cơ chế Pruning (Cắt tỉa nhánh)?
Đệ quy đuôi (Tail Recursion) là gì và tại sao nó giúp tối ưu hóa bộ nhớ ngăn xếp (Stack) hơn đệ quy thông thường?
Đệ quy đuôi là dạng đệ quy mà lời gọi đệ quy là thao tác cuối cùng được thực thi trong hàm trước khi trả về kết quả. Không có bất kỳ phép toán nào khác (như cộng, nhân) được thực hiện sau cuộc gọi đệ quy đó.
- Đệ quy thường:
return n * fact(n - 1). Sau khifact(n - 1)chạy xong, chương trình vẫn phải quay lại để thực hiện phép nhân vớin. Vì vậy, JVM/Compiler bắt buộc phải giữ lại khung ngăn xếp (stack frame) của hàm hiện tại để lưu trữ biếnn. - Đệ quy đuôi:
return fact_tail(n - 1, n * accumulator). Kết quả của lời gọi đệ quy tiếp theo cũng chính là kết quả cuối cùng của hàm hiện tại. - Tối ưu hóa đệ quy đuôi (TCO - Tail Call Optimization): Các trình biên dịch thông minh (như GCC, Kotlin, Swift, Safari JS Engine) sẽ phát hiện đệ quy đuôi và tái sử dụng lại stack frame hiện tại thay vì tạo ra stack frame mới. Thao tác đệ quy đuôi được chuyển đổi ngầm thành vòng lặp (loop), giúp giải quyết triệt để nguy cơ tràn bộ nhớ ngăn xếp (Stack Overflow) với độ phức tạp không gian O(1).
So sánh các cách tính số Fibonacci thứ N bằng Đệ quy thường, Quy hoạch động, và Nhân ma trận về mặt độ phức tạp thời gian và không gian?
Có 3 phương pháp phổ biến để tính số Fibonacci thứ N với hiệu năng khác nhau rõ rệt:
- Đệ quy thông thường:
- Cơ chế: Gọi đệ quy song song
F(n) = F(n-1) + F(n-2). - Hiệu năng: Tốn O(2^n) thời gian vì tính lại các bài toán con trùng lặp quá nhiều. Tốn O(n) không gian cho Stack đệ quy.
- Cơ chế: Gọi đệ quy song song
- Quy hoạch động (DP - Iterative):
- Cơ chế: Lưu 2 giá trị Fibonacci trước đó và tính tiến lên bằng vòng lặp.
- Hiệu năng: Tốn O(n) thời gian (chỉ duyệt 1 vòng lặp) và O(1) không gian (chỉ lưu 2 biến tạm).
- Nhân ma trận (Matrix Exponentiation):
- Cơ chế: Dựa trên công thức toán học luỹ thừa ma trận [ [1, 1], [1, 0] ]^n. Ta tính luỹ thừa bằng phương pháp Chia để trị (Binary Exponentiation).
- Hiệu năng: Tốn O(log n) thời gian và O(log n) không gian (hoặc O(1) nếu lặp). Cực kỳ hữu ích khi N rất lớn (vài tỷ).
Làm thế nào để thiết kế một hệ thống RESTful API hỗ trợ phiên bản (API Versioning) hiệu quả và tương thích ngược tốt?
Có 3 cách tiếp cận phổ biến để thiết kế API Versioning:
- URI Versioning: Ví dụ:
/api/v1/users. Trực quan, dễ cấu hình định tuyến và cache tại CDN. Tuy nhiên làm thay đổi toàn bộ URI khi nâng cấp. - Header Versioning (Custom Header): Ví dụ:
X-API-Version: 1. URI được giữ nguyên, thông tin phiên bản truyền qua request header. Thích hợp cho thiết kế REST tinh khiết nhưng khó test trực tiếp qua trình duyệt. - Content Negotiation (Accept Header): Ví dụ:
Accept: application/vnd.myapi.v1+json. Kiểm soát phiên bản ở mức độ chi tiết nhất dựa trên tài nguyên trả về.
- Best Practices: Luôn đảm bảo khả năng tương thích ngược (Backward Compatibility) bằng cách không xóa hoặc thay đổi kiểu dữ liệu của các trường cũ. Nếu bắt buộc thay đổi lớn (Breaking Change), hãy chuyển sang version mới và duy trì song song phiên bản cũ (Graceful Deprecation) trong một khoảng thời gian báo trước.
Giải thích cơ chế hoạt động của Sharding (Phân mảnh dữ liệu) và sự khác biệt so với Partitioning thông thường?
Cả hai đều dùng để phân tách các bảng dữ liệu quá lớn thành các phần nhỏ hơn để tăng hiệu năng truy vấn, nhưng phạm vi hoạt động khác nhau:
- Partitioning (Phân vùng): Chia một bảng lớn thành nhiều phần nhỏ dựa trên các tiêu chí (Range, List, Hash) nhưng tất cả các phần này vẫn nằm trên cùng một cơ sở dữ liệu và cùng một server vật lý. Nó giúp tối ưu hóa việc quét dữ liệu nhờ loại bỏ các phân vùng không liên quan (Partition Pruning).
- Sharding (Phân mảnh): Chia dữ liệu của một bảng lớn và lưu trữ chúng trên nhiều server vật lý độc lập (Database Nodes) khác nhau. Mỗi node được gọi là một shard.
- Sự khác biệt: Sharding cho phép mở rộng hệ thống theo chiều ngang (Scale Out), vượt qua giới hạn lưu trữ và CPU của một server đơn lẻ. Tuy nhiên, Sharding làm tăng độ phức tạp khi thực hiện truy vấn kết hợp nhiều bảng (Cross-shard joins) và quản lý tính nhất quán của dữ liệu.
ACID là gì? Giải thích chi tiết cơ chế hoạt động của WAL (Write-Ahead Logging) giúp đảm bảo tính bền vững (Durability) trong các hệ quản trị CSDL?
- Khi có yêu cầu thay đổi dữ liệu, thay vì ghi trực tiếp vào các file dữ liệu trên đĩa (rất chậm vì ghi ngẫu nhiên - random I/O), CSDL sẽ ghi các thay đổi này dưới dạng tuần tự vào file Log (WAL log) trên đĩa cứng (rất nhanh vì ghi tuần tự - sequential I/O).
- Sau khi WAL log được ghi thành công xuống đĩa cứng (flushed), giao dịch được coi là đã commit thành công và phản hồi cho client.
- Dữ liệu thực tế trên bộ nhớ RAM sẽ được ghi xuống đĩa cứng sau một khoảng thời gian (quá trình Checkpoint).
- Nếu hệ thống đột ngột mất điện, CSDL sẽ đọc lại file WAL log để khôi phục (Redo) các giao dịch đã commit nhưng chưa kịp ghi xuống đĩa, đảm bảo tính bền vững tuyệt đối.
Làm thế nào để tối ưu hóa kích thước Docker Image (Docker Image Size Optimization) khi viết Dockerfile cho ứng dụng chạy production?
Tối ưu kích thước Docker Image giúp tăng tốc độ build, push/pull image và tiết kiệm bộ nhớ cho hạ tầng. Các best practices bao gồm:
- Sử dụng Multi-stage Builds: Chia Dockerfile thành nhiều giai đoạn build độc lập. Chỉ sao chép các artifacts đã compile hoặc dependencies cần thiết từ stage build sang stage chạy production cuối cùng, bỏ lại toàn bộ SDK và source code gốc.
- Chọn Base Image nhỏ gọn: Thay vì dùng
ubuntuhaynode:latest, hãy sử dụng các phiên bản tối giản như Alpine Linux (node:alpine) hoặc Distroless Images. - Hạn chế số lượng Layer: Mỗi câu lệnh
RUN,COPY,ADDsẽ tạo ra một layer mới. Gộp các lệnhRUN apt-get update && apt-get install -y ... && rm -rf /var/lib/apt/lists/*thành một câu lệnh duy nhất để tránh lưu trữ các file tạm thừa trong các layer trung gian. - Sử dụng file
.dockerignore: Loại bỏ các thư mục phát triển nhưnode_modules,.git,testsđể không bị copy vô ích vào build context.
Mẫu thiết kế Saga (Saga Pattern) giải quyết bài toán giao dịch phân tán (Distributed Transactions) trong kiến trúc Microservices như thế nào?
Trong kiến trúc Microservices, mỗi service quản lý cơ sở dữ liệu riêng, nên ta không thể dùng giao dịch ACID của một CSDL đơn lẻ. Saga Pattern giải quyết vấn đề này bằng cách chia giao dịch lớn thành một chuỗi các giao dịch cục bộ (Local Transactions):
- Cơ chế hoạt động: Mỗi service thực hiện giao dịch cục bộ của mình và phát ra một sự kiện (Event). Service tiếp theo lắng nghe sự kiện đó và thực hiện giao dịch cục bộ của mình. Quá trình tiếp diễn cho đến khi hoàn thành.
- Giao dịch bù (Compensating Transactions): Nếu một bước trong chuỗi gặp lỗi (ví dụ: Thanh toán thất bại), Saga sẽ kích hoạt các giao dịch bù theo thứ tự ngược lại để hoàn tác (rollback) các thay đổi đã được thực hiện ở các bước trước (ví dụ: Hoàn trả lại số lượng hàng đã giữ trong kho).
- Cách thức triển khai:
- Choreography (Phối hợp phi tập trung): Các services tự lắng nghe và phát sự kiện lẫn nhau thông qua Message Broker.
- Orchestration (Phối hợp tập trung): Sử dụng một service điều phối trung tâm (Saga Orchestrator) để ra lệnh trực tiếp cho từng service thực thi.
Phân biệt sự khác nhau giữa StatefulSet và Deployment trong Kubernetes? Khi nào bắt buộc phải dùng StatefulSet?
Cả hai đều dùng để quản lý Pods trong Kubernetes nhưng hướng tới các loại ứng dụng khác nhau:
- Deployment: Dành cho các ứng dụng không trạng thái (Stateless), ví dụ: Web API, Frontend. Các Pods là vô danh, có thể thay thế cho nhau. Khi scale, Pod mới được tạo ra với tên ngẫu nhiên và không giữ lại trạng thái hay dữ liệu của Pod cũ.
- StatefulSet: Dành cho các ứng dụng có trạng thái (Stateful), ví dụ: Database (MySQL, PostgreSQL), Message Queue (Kafka). Các Pods có mã định danh duy nhất, cố định (ví dụ: pod-0, pod-1) và được khởi tạo theo thứ tự nghiêm ngặt.
- Tính liên kết bộ nhớ: Mỗi Pod trong StatefulSet được liên kết chặt chẽ với một PersistentVolume (PV) riêng biệt. Khi một Pod bị crash và được tạo lại, K8s sẽ gắn đúng Persistent Volume cũ của Pod đó vào để đảm bảo dữ liệu không bị mất mát.
So sánh cơ chế hoạt động và tính bảo mật giữa Mã hóa đối xứng (Symmetric Encryption) và Mã hóa bất đối xứng (Asymmetric Encryption)?
Clean Architecture (Kiến trúc sạch) hoạt động theo nguyên lý nào và làm thế nào để đảm bảo Dependency Rule (Luật phụ thuộc)?
Clean Architecture do Robert C. Martin giới thiệu, chia hệ thống thành các vòng tròn đồng tâm với mục tiêu tách biệt mã nguồn nghiệp vụ khỏi các công cụ kỹ thuật (như Database, Web Framework, UI):
- Các tầng cốt lõi: Entities (Nghiệp vụ cốt lõi) -> Use Cases (Luồng nghiệp vụ ứng dụng) -> Interface Adapters (Controllers, Presenters) -> Frameworks & Drivers (Database, Web).
- Luật phụ thuộc (Dependency Rule): Mã nguồn ở vòng tròn bên trong không được phép biết hoặc chứa bất kỳ tham chiếu nào tới mã nguồn ở vòng tròn bên ngoài. Mọi sự phụ thuộc phải luôn hướng từ ngoài vào trong.
- Cách đảm bảo: Sử dụng kỹ thuật Dependency Inversion (DIP). Ví dụ, Use Case cần lưu dữ liệu sẽ không gọi trực tiếp class Database ở ngoài. Thay vào đó, nó định nghĩa một Interface (Port/Gateway) ở trong. Class Database ở ngoài sẽ implement interface đó. Khi chạy, IoC Container sẽ tiêm thực thể database vào Use Case.
Hiện tượng Cache Stampede (hoặc Cache Avalanche) là gì? Làm thế nào để phòng chống hiện tượng này trong các hệ thống chịu tải cao?
- Mutex Lock (Single Flight): Chỉ cho phép request đầu tiên truy cập CSDL để lấy dữ liệu mới và khóa các request khác lại bắt chúng chờ cho đến khi dữ liệu mới được cập nhật vào cache.
- Chạy Background Worker: Tự động cập nhật (refresh) dữ liệu trong cache bằng tác vụ ngầm trước khi key đó hết hạn thực tế.
- Xác suất tính toán sớm (Probabilistic Early Expiration): Cho phép một tỷ lệ nhỏ request tính toán lại giá trị cache trước khi key hết hạn.